

NOTE: There’s now a follow-up to this post, wherein I recreate this bumbling incompetency in Go /Golang
The Challenge
A week or so ago, to tie in with Radio4’s GCHQ: Minority Report documentary, the BBC published a code-breaking challenge set by GCHQ. The challenge took the following format:

They also provided the following clue:
CLUE: The key to unlocking the puzzle is identifying Samuel, Louis and Ludwik. There are links between them!
As soon as I saw the clue and, given we were dealing with some kind of encoding here, I immediately thought Samuel Morse and Louis Braille, although 'Ludwik' didn’t immediately ring any bells. Thanks to the unusual spelling though, it was fairly easy to search the intarwebs and come across LL Zamenhof (or 'Ludwik' to his friends), inventor of the Esperanto, the constructed language.

With three people fitting the names given, who are all famed for inventing some form of language [or way of encoding info], that looked like a pretty solid basis to work from. So let’s take another look at that message which accompanies the code in the puzzle:
If Samuel [Morse] transcribed what Louis [Braille] wrote…
…and Louis [Braille] wrote what Ludwik [Zamenhof] translated
..and Ludwik [Zamenhof] translated what Tim said..
…then what did Tim say?
Then it seems pretty nailed on that we’re looking at an original message [by Tim], which has been translated into Esperanto [by Ludwik], then the Esperanto re-written in Braille [by Louis] and, finally, the Braille transcribed to Morse Code [by Samuel].
So, in order to decode it, we’re going to have to work backwards, going from: Morse > Braille > Esperanto > English
1st Attempt: Pencil and Paper
[Those of you waiting to read the Python shenanigans, hang in there. It’s coming soon!]
Initially, as the cheeky montage below shows, I started trying to work this out using good ol' pencil and paper. However, as I worked through my first ideas and returned only gibberish, I soon realised that, even if my Morse > Braille > Esperanto > English theory was correct, there were several ways to 'interpret' the decoding. So I decided to switch to using Python, which would allow me to run my various theories for decoding the message a lot quicker than drawing a million 'dominoes' on the back of a crossword!

Enter Python
For the sake of plot continuity, we’ll assume that the pencil and paper stuff never happened, we’ll go back to the beginning and I’ll walk you through how I cracked the code using Python.
DISCLAIMER: I’m only an 'occasional tinkerer' when it comes to coding, so this code is doubtless hopelessy clunky and non-Pythonesque. However, one of the great things about Python is that it allows you to hack away clumsily and iterate through a problem til you end up with something that 'does the job'—clunky though it may well be.
ANOTHER SPOILERY DISCLAIMER THING: I had to try a few permutations before I solved this puzzle. So I’m going to record the entire process here, including where I went wrong, as old Mr. 'Stinker' Stinson our maths teacher would have hauled us up out of our chairs by the sideboards, if we failed to show 'our working out'.
Let’s go!…
The first step was to get the coded message into Python. As the Beeb only supplies the puzzle as an image, this meant transcribing it. And, as I was using my Android tablet at the time, this meant transcribing it v-e-e-r-y slowly.
#store coded message as 3-letter sets in a list
message = (
'INA', 'AAA', 'IAN', 'INA', 'AAN', 'AIA', 'IAI', 'AIN',
'AAI', 'AAI', 'AII', 'AIA', 'AAA', 'IAA', 'INN', 'AAI',
'AAA', 'NNI', 'AIN', 'ANI', 'NAA', 'NNN', 'NMA', 'NAA',
'NIA', 'NMN', 'NNA', 'NNA', 'NNN', 'AMM', 'NNN', 'NAN',
'IMA', 'AIN', 'NIA', 'AMN', 'NAM', 'IAN', 'NAA', 'NIN',
'AMM', 'MIA', 'AMA', 'MMI', 'MAA', 'MMA', 'MMA', 'MAA',
'AMA', 'AMA', 'AAM', 'AAA', 'AMA', 'MAA', 'AAM', 'AMA',
'AIM', 'MMM', 'MMM', 'AMA'
)The astute reader will be wondering why I broke the message up into equal sized groups of letters, when transcribing it into Python. This was because [at this stage] I thought the spaces in the coded message might be gaps through which Red Herrings swam, so decided to ignore them. Said reader may also be following up this thought with musings into the seemingly arbitrary decision to make each group three letters long.
Read on and all will be revealed!
Working on the assumption that the 1st version of the coded message is in Morse Code, I noticed that only a few letters are actually used in the message, namely:
A, I, M, N
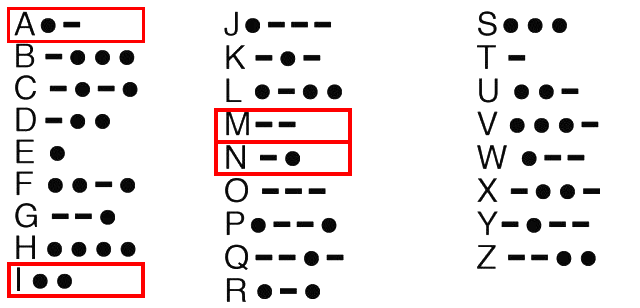
Looking up the Morse Code for those letters, I found the following [which, as you can see, I’ve also stored as a list in Python, using 1 for a dot and 0 for a dash]:
#morse code
morse = {
'A':'10',
'I':'11',
'M':'00',
'N':'01',
}Now, pin that on a braincell for a moment, while we take a look at Braille.
I, for one, had no idea of the structure of Braille. I just knew it was a pattern of raised dots. So, I looked up a Braille alphabet chart:
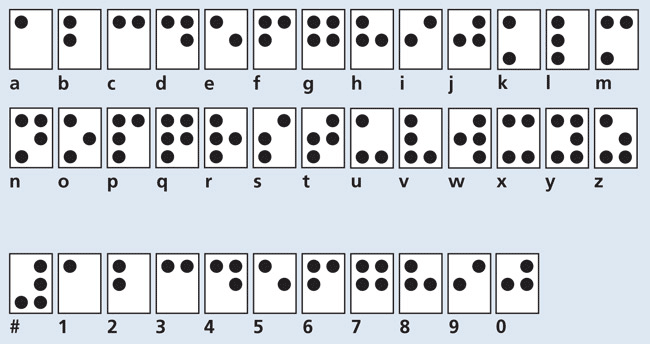
The thing that immediately struck me here was that Braille letters are a bit like dominoes. every one fits into a 2x3 grid. As I had done with the Morse Code letters from the message, I transcribed the letters of the Braille alphabet into a Python list, using 1 to represent a raised dot and 0 to represent a space, thus representing each Braille letter as a group of 6 ones or zeroes [ie top row, middle row and bottom row of the 2x3 'domino']:
#braille alphabet
braille = {
'A':'100000',
'B':'101000',
'C':'110000',
'D':'110100',
'E':'100100',
'F':'111000',
'G':'111100',
'H':'101100',
'I':'011000',
'J':'011100',
'K':'100010',
'L':'101010',
'M':'110010',
'N':'110110',
'O':'100110',
'P':'111010',
'Q':'111110',
'R':'101110',
'S':'011010',
'T':'011110',
'U':'100011',
'V':'101011',
'W':'011101',
'X':'110011',
'Y':'110111',
'Z':'100111'
}Now we’ll see why I broke the original coded message into groups of three letters…
Looking at my translation of the letters used in the message into Morse Code, one thing is quite striking: Although Morse Code contains letters which are represented by 2, 3 or 4 dots & dashes, all of the letters used in the coded message [A,I,M,N] encode to Morse using only two characters.
Let’s unpin that from the braincell and take another look:
#morse code
morse = {
'A':'10',
'I':'11',
'M':'00',
'N':'01',
}Are you thinking what I was at this stage?
The structure of a Braille 'domino' [3 rows of two characters] could be recreated by stacking 3 Morse Code letters on top of each other. So, for example:
#the first three letters of the codded message:
INA
#translate into Morse as:
11, 01, 10
#Which, if we stack them, top to bottom in a 'domino':
11
01
10
#could represent a Braille letter!Again, the astute reader will have realised that the above doesn’t actually represent a real Braille letter but, as I said before, I’m providing the 'warts and all' version here. So this was the theory I was working on at that stage.
Having loaded the basic info into Python, it was time to get up to the elbows in some code and see what we could come up with.
Python: Failed Attempt 01
The Python code is pretty simple.
First we loop through the message, taking each of the 3 letter 'sections' in turn [example 'INA']:
for section in message:Then we look up the two digit Morse Code for each of the 3 letters in that section [example: 11, 01, 10] in the morse[] list and we join them together to give us a six digit Braille code [example: 110110] which we stick into a temporary brailleletter variable for now:
brailleletter = (morse[section[0]]+morse[section[1]]+morse[section[2]])If we’re barking up the right tree, the six-digit code stored in the temporary brailleletter variable [example: 110110] corresponds to a Braille 'domino' value stored in the abovementioned braille[] list. We look up the code in that list and print whichever letter it corresponds to to the screen:
print((list(braille.keys())[list(braille.values()).index(brailleletter)]),end="")So, stick that all together and our script looks like this, so far:
#store coded message as 3-letter sets in a list
message = (
'INA', 'AAA', 'IAN', 'INA', 'AAN', 'AIA', 'IAI', 'AIN',
'AAI', 'AAI', 'AII', 'AIA', 'AAA', 'IAA', 'INN', 'AAI',
'AAA', 'NNI', 'AIN', 'ANI', 'NAA', 'NNN', 'NMA', 'NAA',
'NIA', 'NMN', 'NNA', 'NNA', 'NNN', 'AMM', 'NNN', 'NAN',
'IMA', 'AIN', 'NIA', 'AMN', 'NAM', 'IAN', 'NAA', 'NIN',
'AMM', 'MIA', 'AMA', 'MMI', 'MAA', 'MMA', 'MMA', 'MAA',
'AMA', 'AMA', 'AAM', 'AAA', 'AMA', 'MAA', 'AAM', 'AMA',
'AIM', 'MMM', 'MMM', 'AMA'
)
#morse code
morse = {
'A':'10',
'I':'11',
'M':'00',
'N':'01',
}
#braille alphabet
braille = {
'A':'100000',
'B':'101000',
'C':'110000',
'D':'110100',
'E':'100100',
'F':'111000',
'G':'111100',
'H':'101100',
'I':'011000',
'J':'011100',
'K':'100010',
'L':'101010',
'M':'110010',
'N':'110110',
'O':'100110',
'P':'111010',
'Q':'111110',
'R':'101110',
'S':'011010',
'T':'011110',
'U':'100011',
'V':'101011',
'W':'011101',
'X':'110011',
'Y':'110111',
'Z':'100111'
}
#try morse
print("\n===========================================================")
print("OPTION01 —MORSE")
print("===========================================================\n")
for section in message:
#take 3 letters at a time and convert to morse
# then join 3 morse letters together to create braille letter
brailleletter = (morse[section[0]]+morse[section[1]]+morse[section[2]])
#lookup braille letter
print((list(braille.keys())[list(braille.values()).index(brailleletter)]),end="")
print("\n\n===========================================================\n")OK. Let’s run that and see what we get:
===========================================================
OPTION01 —MORSE
===========================================================
NLTraceback (most recent call last):
File "cracker.py", line 77, in <module>
print((list(braille.keys())[list(braille.values()).index(brailleletter)]),end="")
ValueError: '111001' is not in listWhoops!…
The programme has crashed and burned with a ValueError because the six digit Braille code '111001' we’ve created by joining three Morse letters together does not correspond to any of the six-digit codes representing Braille letters, we’ve got in the braille[] list.
That’s a pretty disappointing start but maybe I just transcribed a letter or digit wrong somewhere, when typing in the various lists —especially as I was using a crappy touch keyboard to do so. It’s too early to throw the baby out with the bathwater yet. Let’s build in a bit of error-handling so the wheels don’t fall off, if we try to look up a non-existent Braille letter.
We’ll wrap that print statement in a try handler and print a question mark if the six-digit brailleletter combo doesn’t match any letters in the braille[] list. Code amended as follows:
#try morse
print("\n===========================================================")
print("OPTION01 —MORSE")
print("===========================================================\n")
for section in message:
#take 3 letters at a time and convert to morse
# then join 3 morse letters together to create braille letter
brailleletter = (morse[section[0]]+morse[section[1]]+morse[section[2]])
#lookup braille letter
try:
print((list(braille.keys())[list(braille.values()).index(brailleletter)]),end="")
#if it doesn't exist, print '?'
except:
print("?",end="")
print("\n\n===========================================================\n")Let’s run it again…
===========================================================
OPTION01 —MORSE
===========================================================
NL?N?R??VV?RLP?VL??ZS??ST????A??M?T?I?SWA?K?????KKBLK?BKH??K
===========================================================Hmmm… Well, at least we didn’t crash this time, but the output isn’t very encouraging. It seems that most of our 3 Morse letters > 1 Braille letter combos don’t actually result in real Braille letters —hence the large number of question marks in the message and its general whiff of gibberish.
Python: Failed Attempt 02
However, I don’t give up that easy. I’m convinced that I’m on the right track. I’m just doing something wrong. I wonder if I’ve messed up when converting Morse to a series of ones and zeroes? I represented the dots with one and the dashes with zero. Maybe it’s the other way round?
Let’s try that. I add another list, this time encoding the Morse letters the opposite way. This time a dot is represented by 0 and a dash by 1:
#alternate morse code
altmorse = {
'A':'01',
'I':'00',
'M':'11',
'N':'10',
}Now, it’s just a case of adapting the previous code to convert the letters in the original coded message into the alternative Morse Code letters and then build those into Braille letters and look them up. [Now you can see why I decided to move from pencil & paper to Python. Imagine the pain of having to do this by hand and look up each individual letter again, against the new alternate Morse Code!]:
#try alt morse
print("\n===========================================================")
print("OPTION02 —ALT MORSE")
print("===========================================================\n")
for section in message:
#take 3 letters at a time and convert to morse
#join 3 morse letters together to create braille letter
brailleletter = (altmorse[section[0]]+altmorse[section[1]]+altmorse[section[2]])
#lookup braille letter
try:
print((list(braille.keys())[list(braille.values()).index(brailleletter)]),end="")
#if it doesn't exist, print '?'
except:
print("?",end="")
print("\n\n===========================================================\n")Light the blue touch paper and….
===========================================================
OPTION02 —ALT MORSE
===========================================================
?????????????????B?I?L???R??L?LO???TZ??K??WG????WW??W??W???W
===========================================================Blimey! —that was even worse! Hardly any of that lot converted into legitimate Braille letters at all.
I’m still convinced the basic concept is sound, so what can the problem be?
I briefly toy with the idea of trying various permutations which use the opposite encoding for the Braille letters [ie. 1 representing a space and 0 representing a raised bump], but that seems highly unlikely. Unlike Morse Code, where you have two distinct 'bits' [dot & dash] and could theoretically decide to represent either as a 1 or 0, with Braille, you only have dots and 'absence of dots' It seems highly unlikely you’d encode for the spaces, rather than the bumps!
Python: Success!
Idly perusing the original coded message again [let’s refresh our memories]:
IN AAAAIAN INAAANAIA IA IAINA AI AA IAIIA IAA AAIAAINN AA IAAANN IAINANI + NA ANNNNMA NAANIANMN NN ANNAN NN AM MNNNN ANI MAAINNIA AM NNAMIA NNAANIN + AM MMIAAMA MMIMAAMMA MM AMAAA MA AM AAAMA AAA MAMAAAAM AM AAIMMM MMMMAMA
…I notice something which has completely passed me by, up until now.
Look carefully at the lines in the message. Each one follows the same pattern of letters and spaces. I suddenly realise that [not for the first time in my life] I’ve over-complicated things by trying to be too clever. Instead of reading the message left to right and grouping each set of three letters together to work from, I’ve already got all the sets of three letters staring me in the face, if I just read the message from top to bottom!

Back to Python and I transcribe each line of the message into a new list, this time preserving the original spacing:
#lined message
messageline01 = ("IN AAAAIAN INAAANAIA IA IAINA AI AA IAIIA IAA AAIAAINN AA IAAANN IAINANI")
messageline02 = ("NA ANNNNMA NAANIANMN NN ANNAN NN AM MNNNN ANI MAAINNIA AM NNAMIA NNAANIN")
messageline03 = ("AM MMIAAMA MMIMAAMMA MM AMAAA MA AM AAAMA AAA MAMAAAAM AM AAIMMM MMMMAMA")Now I do a quick loop through the message, and create a new vertmessage list, this time by building my 3 letter groups from the corresponding letters from the top middle and bottom lines of the message:
vertmessage = []
for index in enumerate(messageline01):
#take letters at a time from each line and group in threes
brailleletter = (messageline01[index[0]]+messageline02[index[0]]+messageline03[index[0]])
vertmessage.append(brailleletter)
print("vertical message: ",vertmessage)Let’s try that….
===========================================================
OPTION03 —VERTICAL READING
===========================================================
vertical message = ['INA', 'NAM', ' ', 'AAM', 'ANM', 'ANI', 'ANA', 'INA', 'AMM', 'NAA', ' ', 'INM', 'NAM', 'AAI', 'ANM'
, 'AIA', 'NAA', 'ANM', 'IMM', 'ANA', ' ', 'INM', 'ANM', ' ', 'IAA', 'ANM', 'INA', 'NAA', 'ANA', ' ', 'ANM', 'INA', '
', 'AAA', 'AMM', ' ', 'IMA', 'ANA', 'INA', 'INM', 'ANA', ' ', 'IAA', 'ANA', 'AIA', ' ', 'AMM', 'AAA', 'IAM', 'AIA', '
ANA', 'INA', 'NIA', 'NAM', ' ', 'AAA', 'AMM', ' ', 'INA', 'ANA', 'AAI', 'AMM', 'NIM', 'NAM', ' ', 'INM', 'ANM', 'IAM',
'NAM', 'ANA', 'NIM', 'INA']Looking good! There are a lot of groups of blank spaces in the list but I’m thinking [hoping!] these will turn out to be the spaces between words. We’ll handle those later.
Meantime we’ve now got a new version of the message to try putting through the original conversion loop. Let’s try that. Slight difference in the code this time. Instead of printing each Braille letter to the screen as we look it up, I’m storing them, as I go along, in a string [optimistically?] called esperanto and then printing this to the screen at the end:
print("\n===========================================================")
print("VERTICAL MESSAGE DECODING:")
print("===========================================================\n")
esperanto = ""
for section in vertmessage:
#take 3 letters at a time and convert to morse
#join 3 morse letters together to create braille letter
#if the 'section' consists of 3 spaces, then interpret it s a single space between words'
#yes. I know this is a bit clunky but it doesn't need importing regex module!
if section == " ":
esperanto += " "
# 'section' wasn't a triple space, so look it up as a braille letter...
# using the previous method
else:
brailleletter = (morse[section[0]]+morse[section[1]]+morse[section[2]])
#lookup braille letter
try:
#if it exists, add it to the esperanto string
esperanto += (list(braille.keys())[list(braille.values()).index(brailleletter)])
#if it doesn't exist, print '?'
except:
esperanto += "?"
# print the constructed esperanto string
print(esperanto)
print("\n===========================================================\n")Fingers crossed. Here we go….
CAUTION: From this point forward lie spoilers. If you don’t want to know the result, please look away now!
===========================================================
VERTICAL MESSAGE DECODING:
===========================================================
NI BEZONAS DIVERSECO DE PENSO EN LA MONDO POR ALFRONTI LA NOVAJI DEFIOJN
===========================================================Get bloody well in! That looks pretty much like Esperanto to me!
The Solution
Now, at this stage, if I was being a real smart arse, I’d write some more sneaky code that takes the above phrase and looks it up on an online Esperanto > English dictionary. But seeing as I’m a lazy git, I’ll just stick it in a couple of online translation sites:
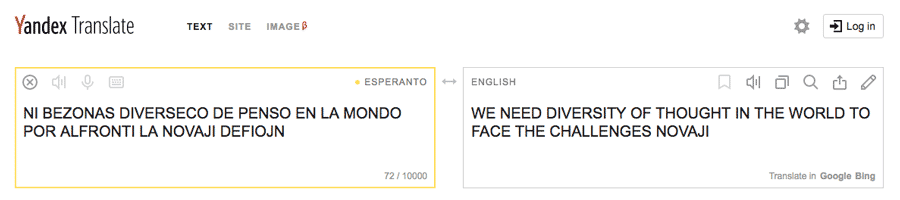
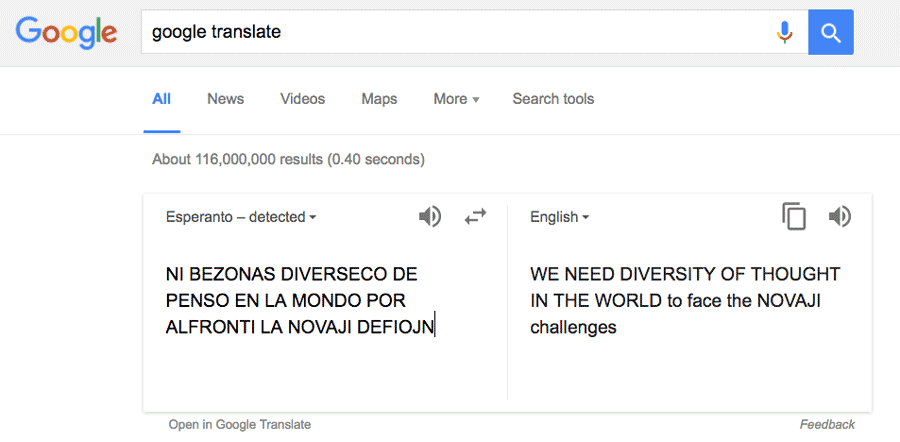
Well, neither of them seemed to like the word NOVAJI much, but I think we can safely assume it means 'NEW'. So the answer to the Beeb’s GCHQ Puzzlebook challenge is:
WE NEED DIVERSITY OF THOUGHT IN THE WORLD TO FACE THE NEW CHALLENGES
An oddly anti-Orwellian sentiment from an organisation which spends a lot of its time keeping a beady eye on the very people in society whose thoughts do divert from the Government’s accepted worldview.
Well, anyway, as you can see, after a couple of false starts, I got there in the end. I hope you enjoyed the walk-through!
…and if you want to cast a mocking eye over the code used in its entirety, you can find it in this snippet on Bitbucket.