

Having dutifully read my previous post about migrating this blog to a Static Site Generator [namely Hugo], you might be wondering whether it’s not a major pain in the nether regions, having to keep reuploading the site, every time I change anything, rather than just posting new content directly via a web interface [a la Tumblr, WordPress, Blogger, etc].
It probably would be, but for the joys of Git.
Git is a system which allows you to keep "Repositories" ie. collections of files in sync across various computers. In this respect, it’s pretty similar to how Dropbox or Jottacloud works, but Git is a bit less user-friendly [you tend to interface with it via a terminal, rather than a GUI], albeit a lot more powerful than those cloud-syncing apps --and it tends to be used more for collaborative projects, rather than simple personal backup and folder sync.
I’m not going to go into detail about the ins and outs of using Git, or how to initialise repositories, fork projects, issue pull requests and all that jazz. For two reasons really:
-
I’m not a hard-core Git user. I find it works for my relatively simple needs and know just enough to get it to do what I want it to do. I wouldn’t presume to advise anyone else on 'proper' Git usage. I’m probably doing it 'all wrong' but it works for me for what I want it to do.
-
If you want a good intro to getting started with Git, there are already plenty out there. I recommend Atlassian’s Bitbucket 101
One last thing, before we 'git' going [D’ye see what I did there?!].
There are quite a few online Git repository hosting services out there. The two biggest and best known are probably GitHub and Bitbucket. I’ve got accounts with both but tend to use Bitbucket more, mainly for the reason that Bitbucket allows you an unlimited number of 'Private' repositories, whilst GitHub only allows you one. A private repository is one where only you have access to the source code. With a public repository, anyone can inspect your code, download it, suggest alterations / additions / bug-fixes, etc. This is why Git is used for a lot of Open Source Software [OSS] projects.

The reason I choose Bitbucket’s additional privacy over GitHub’s requirement that you open most of your repositories to public scrutiny is not because I’m averse to OSS --Au Contraire!-- but because I use the service for things which are only of interest to me, like content for my websites. Apart from that, any 'proper' programming repositories I create are used for my abortive efforts to learn to code. So, again, not of interest to anyone else, unless they have a fetish for reading badly written, poorly functioning code.
The Meat and Potatoes
So, I’ve set up a git repository on Bitbucket containing all the source code for this blog. Whenever I want to do a bit of tinkering, I just sync the latest version from Bitbucket with the local project folder on whatever computer I’m using:
$: cd ~/Sites/stiobhart.net
$:~/Sites/stiobhart.net:
$:~/Sites/stiobhart.net: git pull origin master
From bitbucket.org:madra/stiobhart.net
* branch master -> FETCH_HEAD
Already up-to-date.[My local copy is up-to-date here. If there were any newer files in my repo, I’d get a list of changed files which will then automatically download]
Now I can write my latest blog post on my comp, in Markdown [which Hugo will eventually convert to HTML] and using whatever text editor I want. I also create/download any images or other assets needed for each page and save them into the appropriate local folders. If i want to preview the site locally before committing any changes to the big bad intarwebs, I tell hugo to run its built-in webserver which will serve the pages at http://localhost:1313
$:~/Sites/stiobhart.net: hugo server --watch
##snip
182 pages created
646 tags created
0 categories created
in 330 ms
Watching for changes in /Users/madra/Sites/stiobhart.net/content
Serving pages from /Users/madra/Sites/stiobhart.net/public
Web Server is available at http://localhost:1313
Press ctrl+c to stopThe --watch flag tells Hugo’s server to watch for changes to the source files, rebuild the site automatically and refresh the browser window when this happens.
Once I’ve clicked around my local preview of the site and I’m happy with my new additions, it’s time to upload everything to the live online version of the site. This is a three-step process, but it’s pretty quick and straightforward.
First I have to tell Hugo to build a production version of the site.
When running its own preview server, Hugo will build the site with the base URL set to "http://localhost:1313/" in all the source files, which would obviously balls things up big-style, if I uploaded it 'as is'. I need to rebuild the site, using the correct base URL [in my case http://stiobhart.net/]. To do this, I quit Hugo’s built-in server if it’s running [using CTRL+C] and then re-issue the site building command without the --server flag [or --watch ]. This causes Hugo to rebuild the site in production mode, using proper URLs in place of "localhost" ones.
$:~/Sites/stiobhart.net: hugo
##snip
182 pages created
646 tags created
0 categories created
in 339 msSecond, Push Changes Back to my Repository
Now that I’ve added my new content, and used Hugo to build the production version of the site, it’s time to "push" the changes back up to Bitbucket, so that the site repository on there holds the latest version.
##add all changed files to the 'queue' for uploading
$:~/Sites/stiobhart.net: git add .
##ready 'queue' for uploading with [optional] message
$:~/Sites/stiobhart.net: git commit -m "Some message describing this change"
[master 863399f] Some message describing this change
17 files changed, 468 insertions(+), 29 deletions(-)
create mode 100644 content/2014-12-09-pull-me-push-you.md
create mode 100644 public/2014-12-09-pull-me-push-you/index.html
##snip
create mode 100644 public/tags/version-tracking/index.xml
create mode 100644 static/grafix/bitbucketgithub.jpg
##'push' changes to Repository
$:~/Sites/stiobhart.net: git push origin master
Counting objects: 30, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (29/29), done.
Writing objects: 100% (30/30), 36.22 KiB | 0 bytes/s, done.
Total 30 (delta 18), reused 0 (delta 0)
To git@bitbucket.org:madra/stiobhart.net.git
19da3e4..863399f master -> masterAnd there we have it. Two thirds of the way there now. The site has been rebuilt with the latest content and the changes have been 'pushed' back to the 'Master' repository on Bitbucket. Now all I have to do is login to my webserver which actually hosts the site and download [or 'pull' in Git parlance] the changed files to there from the Master repository on Bitbucket.
Third, Pull Changes from Repository to Webserver
Setting this up was actually a bit tricky. By default Git will just download the whole repository, when you issue a 'pull' request. This would mean that, as well as downloading the "Public" directory, which contains the actual site content, I would be downloading a load of other folders and files which are not part of the final site, but which Hugo uses to build it from. For example; configuration, theme and markdown source files --none of which I want or need on the webserver.
With earlier versions of Git, this was effectively all you could do, without a lot of hacking around but luckily, after a bit of intarwebs searching, I found that newer incarnations of Git do actually have a built-in way of just downloading certain parts of a repository. So I needed to configure Git on my webserver to just download the content of the 'public' directory within the project, which is where the actual static site files live.
This technique is called 'Sparse Checkout' and I found out about it thanks to this thread on Stack Overflow. So, after logging into my webserver and initialising a suitable Git repository there, I had to do the following:
##tell git to use sparse checkout. ie. don't checkout entire project
$madraserver: git config core.sparsecheckout true
##tell Git which directory / files you want to use for sparse checkout
$madraserver: echo "/public/*" >> .git/info/sparse-checkout
##now issue a standard pull request
$madraserver: git pull origin masterAnd that’s it. Now I’ve configured 'sparse checkout', instead of downloading the entire project heirarchy, pull requests on my webserver will only download the relevant files which constitute the site content. OK. Compared to filling in a "Create Post" form on Tumblr’s website, that whole procedure might seem like a load of hassle, but in reality, it’s not. Now everything’s set up and configured, all I need to do is:
-
'Pull' the latest version from Bitbucket to my local comp [if the local version is out-dated]
-
Write & Preview my drivel
-
Tell Hugo to rebuild the site
-
'Push' changes back to Bitbucket
-
Login to my webserver and 'pull' changes from bitbucket
Tada! --Site updated. Outside of the article writing itself, the whole process takes well under a minute.
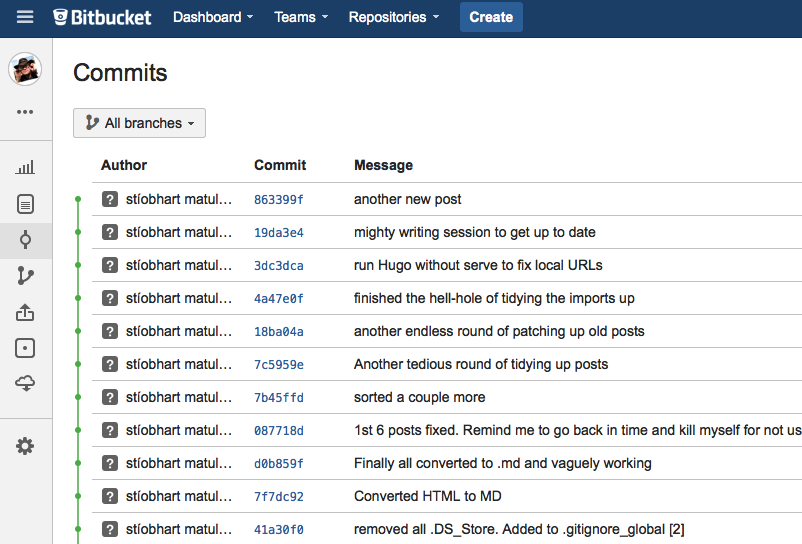
Finally, one more advantage of using a system like Git is that it tracks every change you make to every file in your project. So if you cock something up, or want to roll back to an earlier version of a particular file or project, it’s trivial to do. The entire history of the project is stored in the repository. Here is a sample of the latest meanderings I’ve made in my quest to transfer this blog from Tumblr to Hugo. Any time I’m feeling particularly masochistic, I could roll the project back to an earlier stage and enjoy the torture all over again!:
[Post updated 06 March 2015, to simplify some given commands]